What are good examples that actually motivate the study of recursion?
Computer Science Educators Asked by Ben I. on December 11, 2020
One of the traps of imperative-first is how difficult it becomes to help students make sense of recursion when they finally encounter it. And if those kids are fairly competent iterative programmers, they may also resist the new technique, as they feel perfectly comfortable solving problems without it. Many of the obvious examples of recursion (such as Fibonacci numbers) are either faster or cleaner when done iteratively.
What examples, then, cleanly motivate recursion? To be honest, they don’t have to even be coding examples. What I want is for students to intuitively understand the purpose of this new (to them) technique.
(I am aware of this question of course, but, while it is helpful, is is after an explanatory analogy to clarify recursion, while this question is about finding a clear motivation to study it in the first place.)
21 Answers
One good example is to make permutations of all of the letters in a word of arbitrary length. It's quite tricky to do iteratively, since you essentially have to recreate the program stack to get it done. The recursive solution, however, is clean and clear.
Let the students try to work in pairs on an iterative solution for just five minutes. The goal would not be to actually implement it, but just to think through an approach. Then show them the short and elegant recursive answer and help them to trace through it.
Answered by Ben I. on December 11, 2020
I'm going to focus on student's understanding recursion at a fairly deep level, rather than coding.
First, to really understand recursion you need a sense of its parts. There is the base case, of course and most teachers spend time working on that, but students often miss it. But Before the process hits the base case there is a winding phase working toward the base case and after the base case is reached there is an unwinding phase in which all of the recursive "calls" unwind. In the execution of the algorithm, the winding phase is associated with the execution stack increasing in "height" and the unwinding case is associate with its subsequent shrinking.
One point often missed by novices is that the winding phase has just exactly as many steps as the unwinding phase.
Another point often missed by novices is that work can be done on both the winding and unwinding phases as well as in the base case.
Therefore, to teach recursion you need a set of examples or exercises in which the student can examine all of these in detail.
Complicating this learning is that most students learn recursion in an environment in which they have already learned to count, both upwards and downwards, and that knowledge, while useful in general, can inhibit learning about recursion if the ideas of recursion and counting (by incrementing or decrementing integers) get merged into a single idea.
Therefore, I propose a sequence of active learning exercises, that don't involve coding, but in which the students play roles (stack frames, actually, though you needn't discuss that until later), and which lend themselves to immediate discussion and analysis.
To do these you will want a deck of index cards on which to write instructions of the various roles. The recursions will all be "list-like" so a subset of your students will stand in front of the room in a row. Each student will have a card for the current exercise. Your role is to keep things moving so that the "execution" corresponds to that of a computer. I assume that the students are arranged "left to right" at the front, with the "base-case" person at the right furthest from you.
Exercise one - Work only in the base case.
This is a fairly odd example, not likely to be part of a real program, but it can be instructive. One student's instruction card says that when they are given another card they just read aloud what is on it and then pass it back to the person that gave it to them (This person is the base case). A few others (maybe zero) each have an instruction card that says that when they receive another card they just pass it to the next person in the line, though if it is passed from the left it needs to pass to the right. You have one additional card that says "All Done". You pass this card to the first person, who passes it on, and it should eventually reach the base case and be read aloud. You should then get the card passed back to you.
Talk with the students about the phases (winding, unwinding, base) and how the number of times the card passed in is the same as the number passed out.
Run the "simulation" more than once, with at least one "run" with only the base case. Later you can run it again with a missing base case to see the error that arises.
Exercise two - Work on Winding Phase - Tail Recursion
The instruction card for the base case is that when handed a card he or she should announce how many marks are on the card and then pass it back.
The other student's instructions are that when passed a card "from the left" they just put a mark on it and pass it to the person on the right, but when passed a card from the right they just pass it to the left.
Start the simulation by passing a blank card to the first person (who might be the base case in some "runs". The base-case person should announce the number of people prior to the base case and return the card, through the line, back to you.
At some point you can talk about how this might be mapped to a while loop and avoid all of the return steps: unwinding tail recursion.
As before, have an immediate discussion about what happened to make sure that the students got the points.
You can discuss the fact that the number of marks on the card is like a parameter to the function, also.
Exercise three: Work on the unwind phase only.
The base case instruction is that when handed a card, simply hand it back. The others have instructions that say that they should simply pass on a card if they receive it from the left, but mark it if they receive it from the right and pass it left.
Pass a blank card to the first person and you should get back a card with one mark for each person, but no announcements. You will need to make the announcement of the number of marks.
Exercise four: Work on both winding and unwinding phases.
Here the base-case instruction is that when given a card (from the left) with a certain number of ticks, just write the number of ticks on the card (perhaps on its back) and return it to the person who gave it.
The other student's instruction is that when passed a card from the left just put a tick on it but when passed a card from the right find the largest number on it, double that number, write it on the card and pass it back toward the right. Pass the first person an empty card and make sure you get back the correct result.
Again, a short discussion question/answer session will help solidify the ideas.
While the discussion here was long, these things move quite quickly and only a few minutes are required for each exercise and its retrospective.
However, expect that the students will get it wrong as you go, so your job is to be a coach to make sure it works ok and that the appropriate lessons are learned. Emphasize that the "data card" passed through exactly as many hands on the winding phase as on the unwinding phase.
If you want to emphasize the stack-frame idea a bit more, then in each of the exercises, don't line up the students initially, but pick on them one at a time when you need a new "frame". Give each student their instruction card when they stand up to join. This will require a bit more time, of course, but is more realistic and viewers won't know the depth of recursion beforehand.
I expect that, with the above guidance, you could also devise simple coding exercises with the same characteristics, letting students learn to carefully distinguish the phases of recursion as well as the symmetry.
Answered by Buffy on December 11, 2020
Other than the obvious merge sort, I really like the minimax algorithm, especially when applied to creating a computer player of a simple game.
Start with something simple like tic-tac-toe. When it's your turn, you can think about putting an X on each of the 9 squares. Then you have to think about what your opponent would do in each case. Your opponent would then think about what you would do if they marked an O on each square...
To codify this in a computer player, you can create a pretty simple recursive algorithm that exhaustively searches the space, alternating between whose turn it is, and eventually choosing whichever move leads to the most possible wins, or the fewest losses, whatever. Bonus points for pitting student algorithms against each other.
Then apply that to something more complicated like checkers or chess (or just larger or multidimensional tic-tac-toe). Here, you apply the same basic idea, but you can no longer exhaustively search the whole space because it's too large. So you have to come up with a heuristic and maybe implement alpha-beta pruning.
My point is that the algorithm itself is simple to think about and fun to play with, but it leads to lots of cooler, more complicated topics as well.
See also: Analogy for teaching recursion
Answered by Kevin Workman on December 11, 2020
Another approach, entirely different from my other answer, is to ask students how they might approach the following real-life scenario: they have just been given 1400 paper forms, all filled out by potential enrollees for a program. The forms arrived in the mail and are in no particular order, but they must be sorted into one of 4 geographical regions, and then alphabetically by last name/first name.
The student has been situated in a meeting room with a giant, empty table, and boxes full of forms. The student is told that the sorting needs to be done before the end of the work day. Of course, the activity itself is boring, and the student would love to get out of there as soon as possible. What approach might the student take to the task itself in order to get it done accurately and on time?
Typically, someone will almost immediately suggest sorting the sheets into subpiles. One logical number of subpiles for this first case is 4: divide into 4 piles by geographic region. Now repeat the procedure, dividing into further subpiles. While a true computer algorithm might use 4 piles again, a person would more likely use 26 piles (for the letters of the alphabet). At that point, look at the size of the piles. Repeat the procedure as many times as you need on any piles that are large enough to still be unwieldy.
At some point, you will have a series of tiny piles. A person would probably sort these small piles using some form of insertion or selection sort.
We would now reverse the process, taking our tiny sorted piles, and recombining them into larger and larger fully sorted files. These would be our recursive unwinding steps.
This entire procedure is not dissimilar from a standard mergesort (or, really, a recursive bucket sort). Divide the problem, conquer the smaller pieces, and then recombine. Breaking the problem into smaller subproblems is what makes the entire enterprise more manageable.
What's nice about this procedure as a motivator for examining recursion is that it, with only minor variations, is the natural solution that most people arrive at when faced with such a daunting sorting task because the benefits are clear and natural.
Answered by Ben I. on December 11, 2020
I'd suggest some version of string length, implemented recursively. It's even simpler than factorial. You just break one character off the string, feed it to a recursive call and add one to the result. With that we can teach the essence of recursion.
I find programmers often get confused by trying to "be the computer" working out the recursion to depth rather than working abstractly. So, one trick is to get the aspiring programmers to look at the recursive invocation as a black box rather than to try to think of what's happening at depth. Within the implementation of a recursive function, we want to be able to use the recursive function as if we are merely a client consuming some other function (that already exists and provides some usable capability) with little to no concern about the actual recursion itself.
We always have to switch our hats from provider of an implementation to consuming client. The trick with recursion is to be able to do that with the same function as its implementation is itself a consuming client (of itself).
One approach is to start something like this:
int string_length(char *str) {
if (*str == '�')
return 0;
return 1 + strlen(str+1);
}
With the objective of looking at strlen() as a black box that just works (here: just what it does for us, not how), and then understanding how this string_length() works (e.g. just those three lines of implementation).
Then introduce the idea that since we have confidence that string_length() works — that it does the same thing as strlen() — we can use it in our own implementation: substituting string_length() for strlen().
Answered by Erik Eidt on December 11, 2020
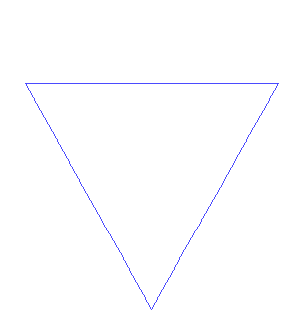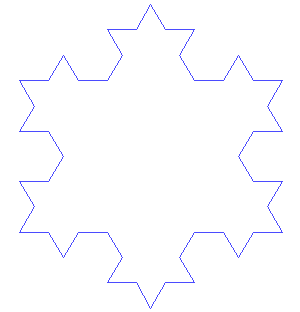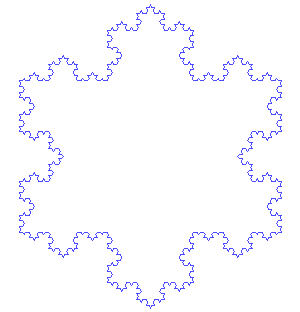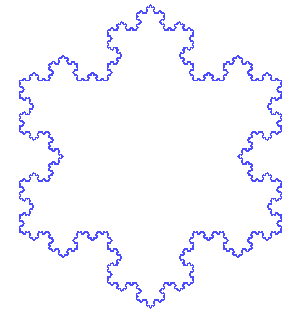
Writing recursive code to output the Snowflake Curve (Koch snowflake) was something that definitely pushed my buttons early on.
It's formed as follows:
The Koch snowflake can be constructed by starting with an equilateral triangle, then recursively altering each line segment as follows:
- divide the line segment into three segments of equal length.
- draw an equilateral triangle that has the middle segment from step 1 as its base and points outward.
- remove the line segment that is the base of the triangle from step 2.
An animation is also available from Wikimedia which shows the snowflake after the first few iterations.
{kind=link}
To generalize further, many Fractals are generated by recursive algorithms and are thus excellent visual representations of recursion in action. The Snowflake/Koch curve is an example of a fractal that is produced by a relatively simple and easily visualizable algorithm making it a great entree into the wider world of fractals.
Answered by bruised reed on December 11, 2020
I find a very easy to understand example for recursion is the folder structure on a computer.
Look through all folders (within a certain location) and... list all .doc files, for example.
First, you look in the location you were given and see what you're looking for... or not, but you see more folders.
Then you take each of those folders, look into them and see what you're looking for... or not, but you see more folders.
Then you take each of those folders... (you get the idea)
It's a simple function to write and understand (at least in pseudocode, actual implementations may vary^^) and a concept that's easy to grasp for even a complete beginner. Introducing the problem and the manual solution, it's already obvious that each time, the same thing happens again and again. Pseudocode implementation is equally simple to write and grasp:
function findFiles(folder) {
look for .doc files, if found add them to fileList.txt
look for folders
for each found folder: findFiles(foundFolder)
}
I've used this example to explain recursion several times, and never had trouble getting the person to understand it. Even non-programmers can grasp the concept like this.
Answered by Syndic on December 11, 2020
The answers are fantastic but what I see you looking for is a motivation for using recursion over other methods. The answer goes back to why one goes to school in the first place. Not to learn what we already know but what others know, which will in the long run prove valuable.
The reason we use recursion generally is not because it is the only solution (well trained CompSci grads can think of little else) but because it is what computers are good at. Particularly; 1.Starting a problem. 2.Putting it onto the stack in order to 3. Go to another problem. This is done all the time. The point of recursion is that each of these steps is for the same purpose. It is not until all the processes are done that they look around to see that there was only one goal, not O sub n goals.
Using minor examples can show off the major achievement of this level of organization.
Answered by Elliot on December 11, 2020
Tree Traversal
Let's compare the recursive and iterative approaches to doing an in-order traversal of a binary search tree.
Recursive approach
void orderedTraversal(const Node *node, void (*f)(int)) {
if (!node) return;
orderedTraversal(node->left, f);
f(node->val);
orderedTraversal(node->right, f);
}
Iterative approach
typedef struct StackNode {
Node *node;
int state;
struct StackNode *next;
} StackNode;
StackNode *push(StackNode *stack, Node *node, int state) {
StackNode *newNode = malloc(sizeof *newNode);
assert(newNode);
newNode->next = stack;
newNode->node = node;
newNode->state = state;
return newNode;
}
StackNode *pop(StackNode *node) {
StackNode *next = node->next;
free(node);
return next;
}
void orderedTraversalIterative(Node *node, void (*f)(int)) {
int state = 0;
StackNode *stack = NULL;
for (;;) {
switch (state) {
case 0:
if (!node) {
state = 2;
continue;
}
stack = push(stack, node, 1);
state = 0;
node = node->left;
continue;
case 1:
f(node->val);
stack = push(stack, node, 2);
state = 0;
node = node->right;
continue;
case 2:
if (!stack) return;
node = stack->node;
state = stack->state;
stack = pop(stack);
continue;
}
}
}
Of course, with a few macros, we can make the logic a bit clearer...
#define CALL(NODE)
stack = push(stack, node, __LINE__);
state = 0;
node = NODE;
goto start;
case __LINE__:
#define RETURN do {
if (!stack) return;
node = stack->node;
state = stack->state;
stack = pop(stack);
goto start;
} while (0)
void orderedTraversalIterative(Node *node, void (*f)(int)) {
int state = 0;
StackNode *stack = NULL;
start: switch (state) {
case 0:
if (!node) RETURN;
CALL(node->left);
f(node->val);
CALL(node->right);
RETURN;
}
}
...and reveal that the iterative approach to this problem is to manually build a call stack mechanism so we can go back to using the recursive approach.
Answered by Ray on December 11, 2020
Show them how they use recursion in solving puzzles in their civilian life.
Sudoku
Ask them how to solve Sudoku.
What's the naive way? You have to iterate through all (roughly) 9^81 numbers, checking each board.
Assuming each check takes on plank second (we're not even close to that in real life), it will take about 3.35843803 × 10^26 years years to solve each Sudoku puzzle.
That's way after the earth falls into a black dwarf sun.
So how do we solve it?
Recursion. Find the "easiest" block to solve (meaning, the one with the least possible variation). Let's say it's the next small board:
| _ | 3 || 4 | _ |
| 2 | _ || _ | 1 |
--------++--------
| 3 | 2 || 1 | _ |
| 4 | _ || 2 | 3 |
So you that first blank could be a 4, 3, 1 or 1.
So what do you do?
You fill a four.
Then you check the board:
| 4 | 3 || 4 | _ |
| 2 | _ || _ | 1 |
--------++--------
| 3 | 2 || 1 | _ |
| 4 | _ || 2 | 3 |
Does it work?
No. There are two fours in the first column.
Try the next, and the next... until you get a one.
| 1 | 3 || 4 | _ |
| 2 | _ || _ | 1 |
--------++--------
| 3 | 2 || 1 | _ |
| 4 | _ || 2 | 3 |
Hey, that works!!
Let's move to the next blank. And you recursively [1] check each square.
How does it work?
Because each problem is a subset of the previous problem.
Here is a sample solver of a given Sudoku board (The website I found it labeled it as "very difficult").
The program solved it in less than a second, going through only 40,000 iterations.
In reality, that's how most people actually solve the problem (ever seen people writing small numbers in each square, erasing ones that don't work? That's your stack!)
[1] In this case you don't need recursion, because the board is too simple. But if you take a real board with moderate difficulty, you need to take steps in, check if they work, and if not, pop out until there's another way to solve it. In short, you push and pop solutions, which is easiest to do with recursion.
A Maze
How do you solve a maze?
You go down one path? If it doesn't work you pop back to the last state where there's hope and try again.
Solving arithmetic problems
How would you solve (1-2)/((1+2)/(3-4))?
Let's assume for a moment that all order-of-operations have been taken care of through parenthesis.
The simplest way would be a recursive-descent parser.
- Lex it. You now have the following lexical array: [
(1-2)/((1+2)/(3-4))] - Start at position 0.
Go block by block:
If it's a regular block (a number): do something like:
DoMath(curVal[pos],curVal[pos+1],curVal[pos+2]) pos = pos+2If it's a 'control character' (a parenthesis in our example):
- Recurse back to 3, with the 'end control character' being a 'close parenthesis'.
- Replace 'n' characters (the length of the inner parenthesis expression) with the the return value.
- If it's an 'end control character' (a 'close parenthesis' or an 'end-of-string tag'): Return the value that's left after all that work.
Answered by cse on December 11, 2020
Construct an immutable nested structure
It's obvious (to us instructors) that in a purely functional language, recursion is the only way to create nested structures. And immutable data is imperative (pun intended) for proper semantical reasoning about values.
So what kind of examples lend themselves to an intuitive recursive approach where an imperative approach is much harder?
Nested data structures like linked lists, trees and graphs are most easily traversed and constructed recursively.
Linked lists are too simple, the tail recursion has the same idea as the equal imperative loop and can be written as such without involving an explicit stack. Graphs are too complicated as keeping state (e.g. to avoid infinite descend) and creating cycles is easiest to do using mutation, and many introductory graph algorithms do keep an explicit queue of nodes. Graphs without cycles are just trees. Here I would avoid n-ary trees where nodes keeps lists/arrays/vectors of children, as those again would typically be accessed in an (imperative) loop, which confuses the students (making the gist of recursion harder to recognise, and obfuscating the base case).
So binary trees it is. A simple tree of integers can be summed, scanned for its maximum and/or minimum, and mapped over with e.g. an incrementing or doubling transformation. It might even be filtered for odd/even numbers. Later you can introduce the respective abstractions (
fold,map,filter) if you want.I would recommend to avoid algorithms for balancing trees here, those are often rather unintuitive when expressed recursively or at least differ much from the imperative approach that is found in most teaching material.
Immutable data structures cannot be re-initialised or changed during traversal. This again prevents imperative solutions e.g. in the
mapexercise.If you are using a functional language in the course, this requirement is probably easy to place. However this doesn't satisfy imperative-minded students who will think "if I could just mutate the data (like in $favouriteLanguage) this task would be much easier".
If you are dealing with an imperative language, you will need to make up some excuses for why immutability is necessary. Constructing not a single but many distinct results helps here. They might be output as a side effect, but are going to get used later after the algorithm ended. Building an animation sequence that can be replayed later (and also rewinded, or run backwards) might be a good idea, which also provides the students with some visualisation.
Computing permutations as suggested by Ben I. is a perfect take on this - instead of just printing all permutations (doable by mutating a sequence) many distinct arrays/lists need to be created. Computing the power set, the subsequences or substrings of an input are similar tasks (and don't even require loops because of the nature of the binary decisions). Here, the concept of sharing between data structures can be introduced as an advantage of immutability later in the course (demonstrated by memory requirements of responses to huge inputs).
Answered by Bergi on December 11, 2020
If the students have learned object-oriented programming then network-traversal or tree-exploration works well because it is easier to visualize one node calling another than to visualize a method calling itself. Start with a directed graph with no cycles so you don't get infinite loops.
//returns true of this is part of the path
public boolean findLastNode(List<Node> pathSoFar)
{
if (this.isLastNode())
{
path.add(this);
return true;
}
for (Node aNeighbor:this.getNeighbors)
{
if (aNeighbor.findLastNode())
{
path.add(this);
return true;
}
}
return false;
}
The code is easy to visualize and draw on the whiteboard because each recursive call moves you across the graph, and you can visualize each node having its own copy of the findLastNode method so you don't have to think of the flow of control reusing variables that are already holding other data.
Answered by Readin on December 11, 2020
Several answers have said things like "We need recursion to handle tree structures." The problem with this type of answer is that the student then asks "Why would we have a tree structure in the first place?"
@Syndic's example of handling directories with subdirectories is probably the best answer, but there are others.
My favorite example where recursion feels natural is Parsing. For many parsing tasks, a recursive descent parser is the easiest approach to take.
For example, parsing JSON:
The top level will something like ParseItem, a function that takes an input stream and returns an data item corresponding to the JSON found there.
This function looks at the first characer to find out what type of item it should parse. Depending on this, it will call ParseObject, ParseNumber, ParseArray, ParseString or whatever.
Now, ParseArray will set up an array and starts parsing items to fill it with. How does it do that? Why, it calls ParseItem! Recursion!
Answered by Stig Hemmer on December 11, 2020
Operating on the key word, motivate, I do believe that Andrew T. had the best choice with Tower of Hanoi. Yes, it's an old one, and it does not lead to anything useful once it's done, (the code is not reusable for some other "real world" problem.) Yet it remains a classic for some reason. I'm going to speculate that the reason is that when presented properly it motivates the students to think about using recursion for other purposes. As to what the motivation is - simple: less work! AKA - unmitigated self-interest. Who doesn't like the idea of getting something done fast and easy, preferring instead to do it the long and hard way while getting the exact same results? That suggests that the motivation comes from the presentation, not from the example used.
With the Tower of Hanoi example, adding in the "legend" of the back story can help with interest, but it can also be a waste of classroom time. Using the legend, or not, is a judgment call for your class and your style. (I have encountered at least three versions of the legend, and I am partial to the version that mentions the walls of the temple crumbling into dust and the world vanishing.)
The key to the presentation is to begin with solving it using an iterative approach. Preferably even before you raise the idea of recursion, leaving the alternative as a way out of the maze later. In a comment, Eric Lippert states that it is easier to solve with an iterative algorithm using these steps and rules: "number the disks in order of size; never move a larger disk onto a smaller disk, never move an odd disk onto an odd disk or an even disk onto an even disk, and never move the same disk twice in a row." That sounds good, and you can present it, just as given, in the classroom. Before trying to code it, however, give it a try physically. Using that rule-set with 5 disks I get the following:
- Only disk available is 1, move 1 from A to B.
- Disks 1 and 2 are available, just moved 1 so only 2 is left. It cannot go on top of 1 (reverse sizes) so move 2 from A to C.
- Disks 1, 2, and 3 are now available. 2 just moved, and 3 cannot go on top of 1 (reverse sizes) or 2 (reverse sizes), so 1 must move. 1 cannot go on 3 (odd on odd), so move 1 from B to C.
- Disks 1 and 3 are available. Disk 1 just moved so we must move 3. It cannot go on 1 (reverse sizes) so move 3 from A to B.
- Disks 1, 3 and 4 are available. Disk 3 just moved, so only 1 and 4 can move. 4 cannot go anywhere (reverse sizes) so 1 moves. 1 cannot go on 3 (odd on odd), so move 1 from C to A.
- Disks 1, 2, and 3 are available. 1 just moved, 3 cannot go anywhere (reverse sizes) so 2 moves. 2 cannot go on 1 (reverse sizes), so move 2 from C to B.
- Disks 1 and 2 are available. 2 just moved, so 1 is next. 1 Can go on top of 2, OR to the empty post.
The given rules offer no guidance for the next move, and computers must have rules to follow.
There is another iterative approach, which does work for creating an algorithm. It has a setup rule, a movement rule and a cycle to repeat. The puzzle usually does not give the arrangement of the posts, only that there are three of them. It is commonly displayed, or presented, with the posts being in a straight line. It can, however, be presented as an arrangement of three posts in a triangular formation, like the image below. In either case, working this iterative approach needs to treat the set of posts as a wrap-around collection, being able to move between the posts infinitely in either direction. The triangular formation makes that easier to visualize than the linear formation.

If we consider the top-left as post "A" (the source post), the top-right as post "B" (the target post), and the bottom-center as post "C" (the working post), then the setup rule is:
For an odd number of disks, the smallest disk moves clockwise, and for an even number of disks the smallest disk moves counter-clockwise.
The movement rule is:
With the disks numbered from smallest, as zero, to largest, disks with an even parity always move the same direction as the smallest disk, and disks with an odd parity always move in the reverse direction.
Finally, the cycle for the moves is:
- Move the smallest disk. 2. Move the only other "legal" move.
Using that two-move cycle, following the movement rule, will solve the puzzle in the smallest possible set of moves. Performing that in class with a 6-disk set shouldn't take very long (about 90 seconds without commentary, 2 or 3 minutes with decision commentary). Especially true if you have previously labeled the disks with their numbers, and marked them in some fashion to show which way they move so that you don't get confused during the demonstration. (Overheads, projector, or animation on screen works as well, but physical objects may have an enhanced long-term effect.)
Now, you have the students primed to learn the power of recursion. The rules for the iterative solution are oh, so simple. Turning those rules into an actual no-fail algorithm, with decisions mapped out, is not so simple after all. As humans, we can see, instantly, where the smallest disk is, which disks are able to move, and almost instantly reject the illegal moves when there are two open disks at the same time. Setting all that human ability into formal codified logic that can be followed blindly and achieve the desired result turns out to be much more difficult than it sounds.
Having not dealt with Hanoi since the middle 1980s, I think I can consider myself as having an almost fresh perspective on the problem. Trying to codify the algorithm for the above rules took up quite a bit of my spare time. I cannot put an amount of clock time to it since it was a "between-times" progress when other issues weren't pressing. Still, it took me the better part of a day to be confident in my algorithm and put it into code. With that in mind, I'm not sure if you should task the students with converting the above rules into a formal algorithm or not. Perhaps you can walk the class through developing one or two of the decisions within the algorithm to give them a sense of the work involved.
The main objective of the presentation up to this point is to help them to see, or experience, how much effort goes into creating the solution using the coding skills they have. Then they are ready to see the power that recursion can give them when the situation is right. Re-address the Hanoi puzzle to show that is can be reduced to a collection of smaller sub-problems that are the same as the original problem, except for size. Any solution that works for the main problem also works for the smaller sub-problems, and any solution that works for the smaller sub-problems also works for the main problem. Use that recognition to design a recursive approach to the solution. Hopefully, the amount of time spent finding the (un-coded) recursive solution is nearly the same as was spent finding the (un-coded) iterative solution, showing that finding the basics for the solution is pretty much the same for either approach. Then the magic happens when the un-coded recursive solution is written into pseudo code, or live code in the chosen language. If you have a coded version of the iterative solution to present, and then they write, or are shown, the recursive solution, they will see that dozens of lines have been reduced to about a dozen (depending on the language used). Reduced lines, with simpler logic means less typing, less chance for bugs and errors, and less work for them.
Once they see the benefits of recursion, you can also deliver the caveats (with examples if you have them) which includes:
- The recursive solution may not be the shortest
- The recursive solution may not be the fastest
- A recursive solution may not exist for a given problem
- A recursive solution might take longer to create than an iterative vesrion
- Recursive solutions can create issues with the stack, and memory management
- Recursion is not, by itself, faster or slower, than iteration
- Recursion has to have the base case built in to the model, there is no outside decision maker
This is also a case where the recursive solution is faster, significantly, than the iterative solution. Running a series of time trials, with the output comment out and disk count set to 25 (33,554,431 moves), the iterative solution averaged 1m22.4s and the recursive solution averaged 0m28.4s.
Granted, my code is in Perl, and most of your classes are in Java, C++, or a functional language, so it would have to be converted for use in your languages. I took advantage of a few of the patterns inherent in the puzzle solution, and stated the "tricks" used in the comments. I did not, however, try for serious optimization or other forms of code cleaning. In spite of that, this is the final version of a tested, and timed, version of the Hanoi puzzle using an iterative approach:
#!/usr/bin/perl
use strict;
use warnings;
use 5.10.0;
my $disks = 20; # How many disks to use for the game.
sub move_tower_iterative { # (height of tower, souce post, destination post, spare post)
my ($height, @names) = @_; # Collect the parameters
my @posts = ([reverse (0 .. $height-1)], [], []); # The post, to track the state of the game
my $rotation = ($height % 2)? 1 : -1; # Direction the smallest disk moves
# 1 is source -> destination -> spare -> source ...
# -1 is source -> spare -> destination -> source ...
my ($disk, $from, $to) = (0) x 2; # Temporary data, pre-loaded for the first move
do {
# Figure out where the disk to be moved will go
$to = ($from + $rotation * (($posts[$from][-1] % 2)? -1 : 1) + 3) % 3;
# Take the disk off the top of one post
$disk = pop $posts[$from];
# Add it to the top of the other post
push $posts[$to], $disk;
# Say what we did
printf "tMove disk from %s to %sn", $names[$from], $names[$to];
# Find the next legal move
if ( 0 != $posts[$to][-1] ) { # Was the smallest disk NOT the last move? Then move it.
# It will be found where the just moved disk would move to, if it was to move again.
$from = ($to + $rotation * (($posts[$to][-1] % 2)? -1 : 1) + 3) % 3;
}
else { # Not moving the smallest disk means finding the one other legal move
while ( # Starting with the same post we just moved from check if ...
( -1 == $#{$posts[$from]} ) # The post is empty
|| ( # OR both
( -1 != $#{@posts[($from + $rotation * (($posts[$from][-1] % 2)? -1 : 1) + 3) % 3]} ) # The destination post is not empty
&& ($posts[$from][-1] > $posts[($from + $rotation * (($posts[$from][-1] % 2)? -1 : 1) + 3) % 3][-1]) # AND has a smaller disk
)
|| ( # OR both
( 0 == $posts[$from][-1]) # The post has the smallest disk
&& ($#{$posts[$from]} != $height-1) # AND the post is not full
)
) { # Keep looking for by cycling to the next post
$from = ++$from % 3;
}
}
} until ($#{$posts[1]} == $height-1); # Stop when the destination post is full
}
move_tower_iterative $disks, "Back-left", "Back-right", "Front" ; # Start moving.
1;
To balance that out, and to show the difference, here is the recursive version, also tested and timed. In this case I've removed the comments, just as a visual enhancement of the difference between the two versions:
#!/usr/bin/perl
use strict;
use warnings;
use 5.10.0;
my $disks = 20;
sub move_tower_recursive {
my ($height, $source, $dest, $spare) = @_;
if ( 1 <= $height) {
move_tower_recursive($height-1, $source, $spare, $dest);
printf "tMove disk from %s to %sn", $source, $dest;
move_tower_recursive($height-1, $spare, $dest, $source);
}
}
move_tower_recursive $disks, "Left side", "Right side", "Center" ;
1;
Answered by Gypsy Spellweaver on December 11, 2020
When teaching recursion, it is important to emphasize that the true power of recursion comes from its ability to branch. This rules out all the factorial and other similarly silly recursion examples much better written as for-loops.
Have your students write a function that, given an open tile in Minesweeper whose value is zero, opens all the tiles in the neighbourhood that are safe to open. I have used this example for about 15 years in intro to Java course, and think it is the best way to show the usefulness of recursion in a first year course.
Solving the subset sum problem in an integer array is another great example of branching recursion that is only three lines of code using recursion, and a lot more without it.
Answered by Ilkka Kokkarinen on December 11, 2020
Since these did not need to be programming examples, here is another example that I like to use and have found illustrative.
When you need to write a method to solve some problem, you must write that method using the things that you already have: the statements in the language, and the methods already in the standard library or written by you. Your job is to find the right combination of these that will achieve the job.
For example, if you need to define the factorial function, you would do so with the definition
$F(n) = n * (n-1) * ... * 2 * 1$
where the right hand side contains a for-loop and a whole bunch of multiplications, two things that you already have in the language. So we can implement factorial using the things that we have.
But imagine this now as some fantasy type of setting, where this equation is a game of tug of war where the left hand side and the right hand side must pull with equal strength to balance each other out. On the left hand side, $F(n)$ is a big strong mountain giant. If the right hand side consists of little hobbits (each multiplication operation), we will necessarily need a large number of hobbits to be able to pull together as hard as the one mountain giant on the left side.
Spotting the self-similarity in the above definition allows us to turn this into an equivalent recursive definition
$F(n) = n * F(n-1)$
which at first seems like cheating, since we are borrowing the function $F$, the thing that we were supposed to define, from the future to be used in its own definition! What do we gain from doing this trick? Well, since $F(n-1)$ is now on the right hand side, it is now a big friendly giant that is pulling for us, instead of pulling against us, in this game of tug of war!
Nothing in that observation depends on the fact that $F$ is particularly the factorial function. In fact, the more complex and powerful the giant is when placed on the left hand side (for example, consider the problem of parsing), the more powerful it is also when it is working for us on the right hand side.
This realization allows us to solve arbitrarily complicated problems by using a slightly smaller version of those problems on the right hand side. In the game of tug of war between one giant and one slightly smaller giant, we only need to add a couple of small hobbits on the right hand side to balance the whole thing, instead of having to put down some large number of small things to balance one big thing. This is the power of recursion.
Answered by Ilkka Kokkarinen on December 11, 2020
When i was introduced to recursion, i felt the same on why learning something i don't need but using iterative approach on complex situations like Tower of hanoi etc., using recursion seems to be more simpler in logic as well as programming.
The reason i like recursion:
You don't need to solve or think about whole solution. You can break the whole problem in smaller ones, and use those solution to solve the bigger problem. And this helps to think more clear logic for your problem.
Algorithms that makes sense using recursion:
- Tower of Hanoi
- Quick sort
- Graph traversal(Inorder, preorder, postorder)
- and so on...
If you want the students to feel interested in it, you can try giving an assignment of solving tower of hanoi using iterative method. And then using recursion, the students will themselves know which method to use where and why :)
Note: Look for ackermann function as well.
Answered by MIB on December 11, 2020
In my first programming class, I "discovered" the concept of recursion on my own, before it was introduced by the instructor. It wasn't the typical use-case for recursion, but it was enough to jump start my thinking.
I was creating a really simple 2D tile based game, and was working on the graphics. I had a function that took an ID number that represented what kind of tile to draw, and the X,Y coords to draw it. I had already implemented grass (ID 1), by simply drawing a green rectangle, with a few pixels of off-green. When I went to draw a Tree (ID 2), the tree was supposed to have a grassy background behind it. I didn't want to duplicate the grass drawing code again for the tree Tile, and after thinking about it for a while, I thought "Hey, I could just call the drawing function again, and tell it to draw the Grass tile at the current coordinates, then draw the tree over top of it."
I asked the teacher if a function was allowed to call its self. He got a strange look on his face, and asked me to show him what I was doing. He explained a little bit about what was actually happening, and told me that what I was doing actually had a name. He said that it would be covered in a lot more detail in a few weeks.
For me, it was a simple way to see the idea of recursion as a real physical thing, without having to deal with the mathematical abstractions that things like the Fibonacci Sequence require.
Answered by Bradley Uffner on December 11, 2020
Water is a good example, when you pour a jug of water compare it to the algorithim the algorithim or water is continually poured until there is no more water left or the base condition is satisfied, leaving you with a solution, comparing a water fall to a bad case of infinite recursion it just continues flowing.
Answered by hoffman on December 11, 2020
I think what makes Factorial and Fibonacci popular as teaching examples is that they have no input data. This means student implementations can start from scratch, instead of being given some boiler-plate data declarations. (Or requiring the students to write code to create a binary tree or something.)
The Ackermann–Péter function A(m,n) has 2 integer inputs and one integer output so it's nice and simple like Factorial (no pointers or references to any data structures). But its natural definition is recursive, and iterative implementation requires a stack of some sort, so a recursive implementation is easier than iterative.
It's not ideal (for testability over a range of inputs) that it grows so quickly, and you may need to introduce the concept of integer overflow (with wraparound, or undefined behaviour in languages like C for signed int). On the other hand, students will probably think it's cool to have a function which can produce such large outputs from small inputs. A(4,2) has 19,729 decimal digits.
But with m=[0..3], the result fits in a 32-bit integer for a wide range of n, so it's testable.
IMO recursive Fibonacci is a really horrible example. It has O(Fib(n)) complexity instead of O(n) time for an a+=b; b+=a; loop. Recursive Factorial at least has the same complexity class as iterative, but it doesn't require keeping any state.
In an assembly-language assignment (especially when args are passed in registers), Factorial also fails to fully test recursion because no registers need to be saved/restored (except the return address for RISC architectures like MIPS that use a link register instead of x86-style call/ret pushing/popping a return address). There's not much difference between an iterative loop and the body of a recursive implementation. You could get implementations that recurse down to the bottom and then just multiply by an increasing counter while returning back up the call chain.
Recursive Fibonacci avoids this problem: needing to make two separate calls from the same function means it can't degenerate into a loop. But we'd like to reject Fib because it makes recursion look like a stupid way to make programming harder, especially in assembly language.
(Do people really give recursive Fibonacci assignments in assembly language? Yes, they do, and Stack Overflow has the questions from their students to prove it. It is one of the simplest doubly-recursive functions (significantly simpler to implement in asm than Ackermann), but it's maybe so simple that it's not as obvious which state is the "important" state that needs to be saved/restored across child calls.)
A recent Stack Overflow question on MIPS assembly (from a student assigned this homework) appears to have found some useful middle ground here with a function that has similar doubly-recursive structure to Fibonacci but is less trivial, making an iterative implementation less obvious.
And also simply not being a well-known function means that there aren't implementations of it all over the web in many languages, reducing the temptation to copy/paste.
if n>5:f(n) = n*f(n-1) - f(n-3) + n-23- else
n<=5basecasef(n) = 15 - 2n
An iterative implementation is still easily possible and obviously more efficient, especially for large n without memoization. But this has a couple useful features that make it better than Fib(n):
- The base case includes more
nvalues, and is not totally trivial. Initializing vars for an iterative implementation would take some care. - Using
f(n-3)and skippingf(n-2)means iterative would have to keep more temporaries, but doesn't add complexity to a recursive case. - Using the original
nafter both of the recursive calls (to multiply the return value, or add to the total) motivates properly keeping it around. (vs. maybe writing an asm function that preserves its input register, and just decrementing that again to create an input for the next call. That would work but is totally non-standard for normal C calling conventions.) - Clever students will notice that
ncan be destroyed by the 2nd recursive call, doingn - 23 + n*f(n-1)early because integer+is associative. Otherwise they'll have to save both the first return value and the originalnif they evaluate the expression in the order written. - It's not Fibonacci so it's not recognizable as a well-known thing that can be looked up or that some students will already know about.
Tree traversal is one of the best example use-cases for recursion, because you need to remember where you've been at each step of the problem, so any solution needs a stack data structure. Using recursion lets you use the call-stack as your stack.
But you need a tree to traverse, so it's not as "simple" as Factorial.
And it's easy to see that it's a useful thing to do.
Answered by Peter Cordes on December 11, 2020
From Douglas Hofstader's Metamagical Themas, comes the idea of the Porpuquine.
A nine quilled porpuquine has nine quills, each of which is an eight quilled porpuquine. Of course an eight quilled porpuquine has exactly eight quills, each of which is a seven quilled porpuquine. Etc.
Of course, you can explore Quine. And you can do some computing.
The more complete story in the book is worth a look, of course.
Answered by Buffy on December 11, 2020
Add your own answers!
Ask a Question
Get help from others!
Recent Answers
- Peter Machado on Why fry rice before boiling?
- Lex on Does Google Analytics track 404 page responses as valid page views?
- Joshua Engel on Why fry rice before boiling?
- Jon Church on Why fry rice before boiling?
- haakon.io on Why fry rice before boiling?
Recent Questions
- How can I transform graph image into a tikzpicture LaTeX code?
- How Do I Get The Ifruit App Off Of Gta 5 / Grand Theft Auto 5
- Iv’e designed a space elevator using a series of lasers. do you know anybody i could submit the designs too that could manufacture the concept and put it to use
- Need help finding a book. Female OP protagonist, magic
- Why is the WWF pending games (“Your turn”) area replaced w/ a column of “Bonus & Reward”gift boxes?